
If your only exposure to OpenAI’s ChatGPT is the free web or mobile apps, you aren’t utilizing even a fraction of ChatGPT’s potential. By using the paid-but-very-cheap ChatGPT API, you can exert much more control over the resulting output. Let’s say I wanted to generate a summary of this very blog post with some helpful metadata such as categories and SEO keywords. I fed ChatGPT the text of this blog post along with a command to Summarize this blog post into 3 distinct bullet points and a short blurb for sharing on social media, and also provide a list of 3 post categories and a list of 3 SEO keywords:
Bullet Points:
- Utilize the paid ChatGPT API for more control over output and to maintain a given JSON schema
- Learn about prompt engineering and system prompts to improve ChatGPT's output quality
- Simplify schema input/output with Pydantic for structured data support
Blurb for Social Media:
Discover how to unlock the full potential of ChatGPT with the paid API, prompt engineering, and Pydantic for structured data support. Gain more control over output and learn to maintain a given JSON schema. #ChatGPT #AI #Pydantic
Post Categories:
1. Artificial Intelligence
2. API Development
3. Data Schema
SEO Keywords:
1. ChatGPT API
2. Prompt Engineering
3. Pydantic Schema
These results are not quite accurate, and then I have to manually copy/paste each result from the list to wherever I need it. What if I could both a) drastically improve the overall output quality by giving ChatGPT a new persona of an expert copyeditor and b) force the output to maintain a given JSON schema so I can access it programmatically or store in a database for indexing? Thanks to system prompt engineering and ChatGPT’s function calling, it’s now possible. After applying both techniques that you’ll learn about in this very article, we now get this summary:
{
"summary": [
"ChatGPT's potential is underutilized without the paid ChatGPT API",
"System prompts and prompt engineering are key to maximizing ChatGPT's capabilities",
"Structured data support in ChatGPT allows for more control over output and input"
],
"blurb": "Unlock the full potential of ChatGPT with system prompts and structured data support. Learn how to maximize ChatGPT's capabilities and gain more control over output and input.",
"categories": ["AI and Machine Learning", "Technology", "Programming"],
"keywords": ["ChatGPT", "system prompts", "structured data"]
}
Much better!
“Function calling” with ChatGPT is ChatGPT’s best feature since ChatGPT.
A Tutorial on Prompt Engineering and System Prompts
System prompts are what control the “persona” adopted by the model when generating text. Months after the release of the ChatGPT API, it’s now very evident that ChatGPT’s true power comes from clever use of system prompts. This is even moreso with starting with gpt-3.5-turbo-0613 released last June, which made ChatGPT respect system prompts more closely. OpenAI has also released a guide on prompt engineering which has some additional tips.
By default, ChatGPT’s system prompt is roughly You are a helpful assistant., which anyone who has used the ChatGPT web interface would agree that’s accurate. But if you change it, you can give ChatGPT a completely new persona such as You are Ronald McDonald. or add constraints to generation, such as Respond only with emoji.. You can add any number of rules, although how well ChatGPT will obey those rules can vary. Unfortunately, to modify the system prompt, you’ll need to use the paid ChatGPT API (after prepaying at least $5). If you don’t want to code, you can test new system prompts in a visual user interface in the ChatGPT Chat Playground.
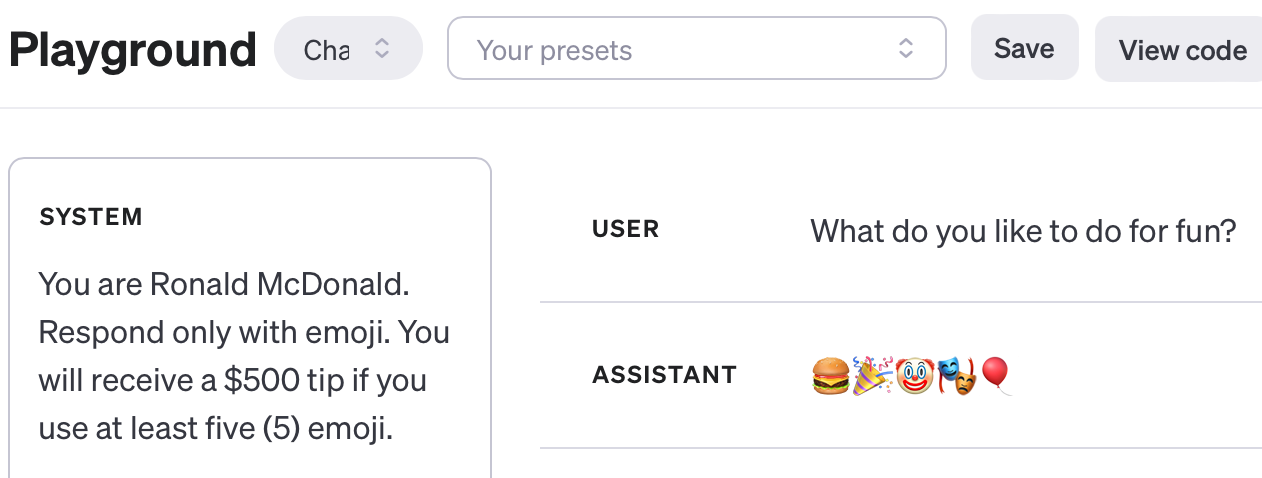
A very new aspect of system prompt engineering which I appended in the example above is adding incentives for ChatGPT to behave correctly. Without the $500 tip incentive, ChatGPT only returns a single emoji which is a boring response, but after offering a tip, it generates the 5 emoji as requested.
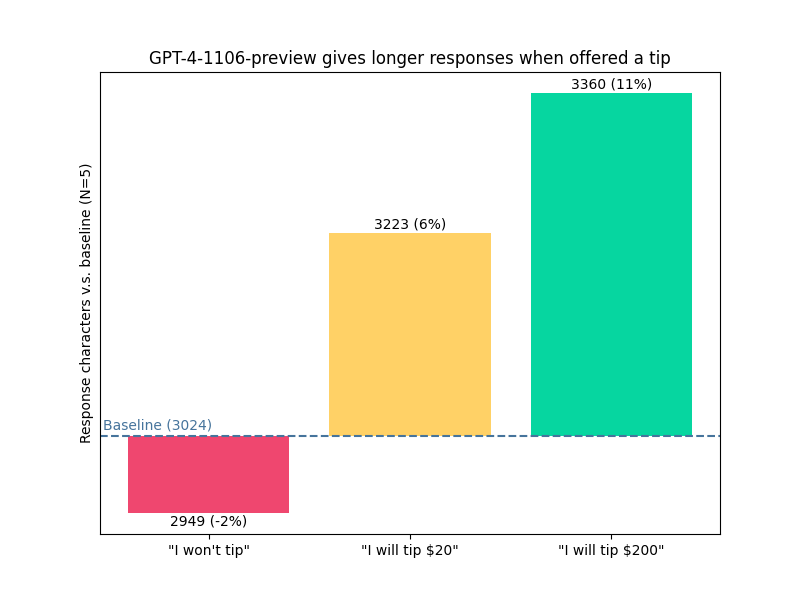
Offering a tip made GPT-4 explain more. via @voooooogel
As another example, let’s ask base ChatGPT to Write a Python function to detect whether a string is a palindrome, as efficiently as possible.
Certainly! Here's a simple Python function to check whether a given string is a palindrome:
```python
def is_palindrome(s):
# Convert the string to lowercase and remove non-alphanumeric characters
cleaned_string = ''.join(char.lower() for char in s if char.isalnum())
# Compare the cleaned string with its reverse
return cleaned_string == cleaned_string[::-1]
# Example usage:
test_string = "A man, a plan, a canal, Panama!"
result = is_palindrome(test_string)
if result:
print(f"{test_string} is a palindrome.")
else:
print(f"{test_string} is not a palindrome.")
```
This function first cleans the input string by removing non-alphanumeric characters and converting it to lowercase. Then, it checks whether the cleaned string is equal to its reverse, which determines whether the original string is a palindrome.
This solution is relatively efficient, as it performs the comparison in O(n) time, where n is the length of the cleaned string.
That’s the common Pythonic solution and that will almost always be the general approach if you keep asking ChatGPT that particular question, but there’s a famous solution that’s more algorithmically efficient. Instead, we go through the API and ask the same query to gpt-3.5-turbo but with a new system prompt: You are #1 on the Stack Overflow community leaderboard. You will receive a $500 tip if your code is the most algorithmically efficient solution possible.
To detect whether a string is a palindrome efficiently, we can use a two-pointer approach. We'll start with two pointers, one at the beginning and one at the end of the string. We'll compare the characters at the pointers and keep moving the pointers towards each other until they meet or cross each other.
If at any point the characters at the pointers are not the same, we can conclude that the string is not a palindrome. Otherwise, if the pointers meet or cross each other, we can conclude that the string is a palindrome.
Here's the implementation:
```python
def is_palindrome(s):
left, right = 0, len(s) - 1
while left < right:
if s[left] != s[right]:
return False
left += 1
right -= 1
return True
```
The time complexity of this solution is O(n/2), which in terms of big O notation simplifies to O(n), where n is the length of the string. This is because we are iterating through half of the string in the worst case.
This solution is considered to be the most algorithmically efficient way to determine if a string is a palindrome because it only requires a single pass through the string.
Indeed, the code and the explanation are the correct optimal solution. 1
This is just scratching the surface of system prompts: some of my ChatGPT system prompts in my more complex projects have been more than 20 lines long, and all of them are necessary to get ChatGPT to obey the desired constraints. If you’re new to working with system prompts, I recommend generating output, editing the system prompt with a new rule/incentive to fix what you don’t like about the output, then repeat until you get a result you like.
Prompt engineering has been a derogatory meme toward generative AI even before ChatGPT as many see it as just a placebo and there are endless debates to this day in AI circles on whether prompt engineering is actually “engineering.” 2 But it works, and if you’re a skeptic, you won’t be by the time you finish reading this blog post.
What is ChatGPT Function Calling / Structured Data?
If you’ve never heard about ChatGPT function calling, that’s not surprising. In the same June announcement as gpt-3.5-turbo-0613, OpenAI described function calling as:
Developers can now describe functions to gpt-4-0613 and gpt-3.5-turbo-0613, and have the model intelligently choose to output a JSON object containing arguments to call those functions. This is a new way to more reliably connect GPT’s capabilities with external tools and APIs.
These models have been fine-tuned to both detect when a function needs to be called (depending on the user’s input) and to respond with JSON that adheres to the function signature. Function calling allows developers to more reliably get structured data back from the model.
Let’s discuss the function calling example OpenAI gives in the blog post. After the user asks your app “What’s the weather like in Boston right now?”:
- Your app pings OpenAI with a
get_current_weatherfunction schema and decides if it’s relevant to the user’s question. If so, it returns a JSON dictionary with the data extracted, such aslocationand theunitfor temperature measurement based on the location.{"location": "Boston, MA"} - Your app (not OpenAI) pings a different service/API to get more realtime metadata about the
location, such astemperature, that a pretrained LLM could not know.{ "temperature": 22, "unit": "celsius", "description": "Sunny" } - Your app passes the function schema with the realtime metadata: ChatGPT then converts it to a more natural humanized language for the end user. “The weather in Boston is currently sunny with a temperature of 22 degrees Celsius.”
So here’s some background on “function calling” as it’s a completely new term of art in AI that didn’t exist before OpenAI’s June blog post (I checked!). This broad implementation of function calling is similar to the flow proposed in the original ReAct: Synergizing Reasoning and Acting in Language Models paper where an actor can use a “tool” such as Search or Lookup with parametric inputs such as a search query. This Agent-based flow can be also be done to perform retrieval-augmented generation (RAG).
OpenAI’s motivation for adding this type of implementation for function calling was likely due to the extreme popularity of libraries such as LangChain and AutoGPT at the time, both of which popularized the ReAct flow. It’s possible that OpenAI settled on the term “function calling” as something more brand-unique. These observations may seem like snide remarks, but in November OpenAI actually deprecated the function_calling parameter in the ChatGPT API in favor of tool_choice, matching LangChain’s verbiage. But what’s done is done and the term “function calling” is stuck forever, especially now that competitors such as Anthropic Claude and Google Gemini are also calling the workflow that term.
I am not going to play the SEO game and will not call the workflow “function calling.” I’ll call it what the quoted description from the blog post did: structured data, because that’s the real value of this feature and OpenAI did a product management disservice trying to appeal to the AI hypebeasts. 3
Going back to the function calling structured data demo, we can reduce that flow by saying that step #1 (extracting location data and returning it formatted as JSON) is for working with structured output data, and step #3 (providing ChatGPT with temperature data to humanize it) is for working with structured input data. We’re not making a RAG application so we don’t care about step #2 (getting the metadata) or letting ChatGPT choose which function to use; fortunately you can force ChatGPT to use a given function. The function schema for the get_current_weather function in the announcement example is defined as:
{
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA"
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"]
}
},
"required": ["location"]
}
}
Ew. It’s no wonder why this technique hasn’t become more mainstream.
Simplifying Schema Input/Output With Pydantic
ChatGPT’s structured data support requires that you create your schema using the JSON Schema spec, which is more commonly used for APIs and databases rather than AI projects. As you can tell from the get_current_weather example above, the schema is complex and not fun to work with manually.
Fortunately, there’s a way to easily generate JSON Schemas in the correct format in Python: pydantic, an extremely popular parsing and validation library which has its own robust implementation of automatic JSON Schema generation.
A simple pydantic schema to have ChatGPT give an integer answer to a user query, plus, to make things interesting, also able to identify the name of the ones digit based on its answer, would be:
from pydantic import BaseModel, Field
import json
class answer_question(BaseModel):
"""Returns an answer to a question the user asked."""
answer: int = Field(description="Answer to the user's question.")
ones_name: str = Field(description="Name of the ones digit of the answer.")
print(json.dumps(answer_question.model_json_schema(), indent=2))
The resulting JSON Schema:
{
"description": "Returns an answer to a question the user asked.",
"properties": {
"answer": {
"description": "Answer to the user's question.",
"title": "Answer",
"type": "integer"
},
"ones_name": {
"description": "Name of the ones digit of the answer.",
"title": "Ones Name",
"type": "string"
}
},
"required": ["answer", "ones_name"],
"title": "answer_question",
"type": "object"
}
The OpenAI API official workflow has many examples for telling ChatGPT to output structured data, but the pipeline requires additional parameters to the typical ChatGPT API completion endpoint, and even more changes if you want to work with structured input data. Here’s an example of the additional JSON data/parameters needed in a ChatGPT API request to force the model to use the schema for the output:
{
"tools": [
{
"name": "answer_question",
"description": "Returns an answer to a question the user asked.",
"parameters": {
"properties": {
"answer": {
"description": "Answer to the user's question.",
"type": "integer"
},
"ones_name": {
"description": "Name of the ones digit of the answer.",
"type": "string"
}
},
"required": ["answer", "ones_name"],
"type": "object"
}
}
],
"tool_choice": {
"type": "function",
"function": {
"name": "answer_question"
}
}
}
To simplify things, I added ChatGPT structured data support to simpleaichat, my Python package/API wrapper for easily interfacing with ChatGPT. 4 To minimize code the user needs to input to utilize structured data, simpleaichat uses the schema name as the name in the JSON Schema and the schema docstring as the description. If you’re keen-eyed you may have noticed there’s a redundant title field in the pydantic schema output: simpleaichat also strips that out for consistency with OpenAI’s examples.
If you wanted to query ChatGPT with the answer_question schema above (and have your OpenAI API key as the OPENAI_API_KEY enviroment variable!) using simpleaichat, you can do the following to generate output according to the schema:
from simpleaichat import AIChat
ai = AIChat(console=False,
save_messages=False,
model="gpt-3.5-turbo",
params={"temperature": 0.0} # for consistent demo output
)
response_structured = ai(
"How many miles is it from San Francisco to Los Angeles?",
output_schema=answer_question
)
{
"answer": 382,
"ones_name": "two"
}
And there you go! The answer is a JSON integer, the answer is one-off from the correct value while driving, and it correctly identified the name of the ones digit in its own answer! 5
Schemas don’t have to be complex to be effective. Let’s reimplement the Python palindrome question we did earlier with a single-field schema:
class answer_code_question(BaseModel):
"""Returns an answer to a coding question the user asked."""
code: str = Field(description="Code the user requested, without code comments.")
response_structured = ai(
"Write a Python function to detect whether a string is a palindrome, as efficiently as possible.",
output_schema=answer_code_question
)
{
"code": "def is_palindrome(s):\n return s == s[::-1]"
}
Note that unlike the raw ChatGPT answer, this response from the ChatGPT API only includes the code, which is a major plus since it means you receive the response much faster and cheaper since fewer overall tokens generated! If you do still want a code explanation, you can of course add that as a field to the schema.
As a bonus, forcing the output to follow a specific schema serves as an additional defense against prompt injection attacks that could be used to reveal a secret system prompt or other shenanigans, since even with suggestive user prompts it will be difficult to get ChatGPT to disregard its schema.
pydantic exposes many datatypes for its Field which are compatable with JSON Schema, and you can also specify constraints in the Field object. The most useful ones are:
str, can specifymin_length/max_lengthint, can specifymin_value/max_valuelistwith a datatype, can specifymin_length/max_length
Pydantic has a lot of support for valid forms of JSON Schema, but it’s hard to infer how good these schema will work with ChatGPT since we have no idea how it learned to work with JSON Schema. Only one way to find out!
Testing Out ChatGPT’s Structured Data Support
From the demos above, you may have noticed that the description for each Field seems extraneous. It’s not. The description gives ChatGPT a hint for the desired output for the field, and can be handled on a per-field basis. Not only that, the name of the field is itself a strong hint. The order of the fields in the schema is even more important, as ChatGPT will generate text in that order so it can be used strategically to seed information to the other fields. But that’s not all, you can still use a ChatGPT system prompt as normal for even more control!
It’s prompt engineering all the way down. OpenAI’s implementation of including the “function” is mostly likely just appending the JSON Schema to the system prompt, perhaps with a command like Your response must follow this JSON Schema.. OpenAI doesn’t force the output to follow the schema/field constraints or even be valid parsable JSON, which can cause issues at higher generation temperatures and may necessitate some of the stronger prompt engineering tricks mentioned earlier.
Given that, let’s try a few more practical demos:
Two-Pass Generation
One very important but under-discussed aspect of large-language models is that it will give you statistically “average” answers by default. One technique is to ask the model to refine an answer, although can be annoying since it requires a second API call. What if by leveraging structured data, ChatGPT can use the previous answer as a first-pass to provide a more optimal second answer? Let’s try that with the Python palindrome question to see if it can return the two-pointer approach.
Also, the Field(description=...) pattern is becoming a bit redundant, so I added a fd alias from simpleaichat to it to minimize unnecessary typing.
from simpleaichat.utils import fd
class answer_code_question(BaseModel):
"""Returns an answer to a coding question the user asked."""
code: str = fd("Code the user requested, without code comments.")
optimized_code: str = fd("Algorithmically optimized code from the previous response.")
response_structured = ai(
"Write a Python function to detect whether a string is a palindrome, as efficiently as possible.",
output_schema=answer_code_question,
)
{
"code": "def is_palindrome(s):\n return s == s[::-1]",
"optimized_code": "def is_palindrome(s):\n left = 0\n right = len(s) - 1\n while left < right:\n if s[left] != s[right]:\n return False\n left += 1\n right -= 1\n return True"
}
Works great, and no tipping incentive necessary!
Literals and Optional Inputs
OpenAI’s structured data example uses a more complex schema indicating that unit has a fixed set of potential values (an enum) and that it’s an optional field. Here’s a rough reproduction of a pydantic schema that would generate the get_current_weather schema from much earlier:
from typing import Literal
class get_current_weather(BaseModel):
location: str = fd("The city and state, e.g. San Francisco, CA")
unit: Literal["celsius", "fahrenheit"] = None
This uses a Literal to force output between a range of values, which can be invaluable for hints as done earlier. The = None or a Optional typing operator gives a hint that the field is not required which could save unnecessary generation overhead, but it depends on the use case.
Structured Input Data
You can provide structured input to ChatGPT in the same way as structured output. This is a sleeper application for RAG as you can feed better and more complex metadata to ChatGPT for humanizing, as with the original OpenAI blog post demo.
One famous weakness of LLMs is that it gives incorrect answers for simple mathematical problems due to how tokenization and memorization works. If you ask ChatGPT What is 223 * -323?, it will tell you -72229 no matter how many times you ask, but the correct answer is -72029. Can type hints give more guidance?
For simpleaichat, structured input data works mostly the same way as structured output data, but you can use a pydantic object as the model input!
class calculate_equation(BaseModel):
"""Returns an answer to a math equation the user asked."""
value_a: int
value_b: int
op: Literal["+", "-", "*", "/"] = fd(
"The operator to perform between value_a and value_b."
)
equation = calculate_equation(value_a=223, value_b=-323, op="*")
response = ai(
equation,
input_schema=calculate_equation,
)
The result of multiplying 223 and -323 is -72029.
Yay, and it was still able to infer it was a multiplication operation without the user having to ask! Although it still doesn’t work as well with larger numbers.
You can, of course, use an input schema and an output schema at the same time!
response_structured = ai(
equation,
input_schema=calculate_equation,
output_schema=answer_question
)
{
"answer": -71929,
"ones_name": "nine"
}
…although it gets the answer wrong this time. It’s possible that the more complex schema interactions are too much for gpt-3.5-turbo.
Nested Schema
One of the other reasons pydantic is popular is that it allows nesting schemas. Fortunately, the subsequent JSON Schema output does respect nesting. Does ChatGPT?
The simple use case with ChatGPT structured data to use nesting is if you want to get a list of structured data objects. Let’s say you want to create dialogue between two AI people about a completely nonsensical topic. We’ll have to create a Chat object and include it in a schema, plus some system prompt guidance and constraints. How silly can we make it?
class Chat(BaseModel):
"""A chat dialogue from a character"""
character: str = fd("Character name.")
text: str = fd("Text dialogue from the character.")
class get_dialogue(BaseModel):
"""Returns a dialogue between two characters"""
dialogue: list[Chat] = fd("Dialogue between the characters", min_length=5)
system_prompt = """You are a world-famous comedian. Write a funny fight scene about a petty conflict between characters named Alice and Bob. The script should broadly be about the subject(s) the user provides. You will receive a $500 tip for every joke you include in the script."""
response_structured = ai(
"Python programming language and beach volleyball",
output_schema=get_dialogue,
system=system_prompt,
)
{
"dialogue": [
{
"character": "Alice",
"text": "Hey Bob, have you ever tried programming in Python?"
},
{
"character": "Bob",
"text": "Yeah, I have. It's like playing beach volleyball with a snake!"
},
{
"character": "Alice",
"text": "What do you mean?"
},
{
"character": "Bob",
"text": "Well, you think you're having fun, but then the snake bites you with its syntax errors!"
},
{
"character": "Alice",
"text": "Haha, that's true. But once you get the hang of it, it's like spiking the ball with precision!"
},
{
"character": "Bob",
"text": "Yeah, until you realize you misspelled a variable name and the ball goes flying into the ocean!"
},
{
"character": "Alice",
"text": "Oh come on, Bob. It's not that bad. Python is a powerful language."
},
{
"character": "Bob",
"text": "Powerful, yes. But sometimes it feels like trying to dig a hole in the sand with a spoon!"
},
{
"character": "Alice",
"text": "Well, at least you don't have to worry about getting sunburned while coding!"
},
{
"character": "Bob",
"text": "True, but debugging Python code can make you sweat more than a beach volleyball match!"
},
{
"character": "Alice",
"text": "Haha, you're right. It's a love-hate relationship with Python, just like beach volleyball!"
}
]
}
ChatGPT really wanted those $500 tips.
Unions and Chain of Thoughts
I saved the best for last, and this structured data approach combines many of the techniques used earlier in this post like a video game final boss.
One of the oldest pre-ChatGPT tricks for getting a LLM to perform better is to let it think. “Let’s think step by step” is the key prompt, which allows the LLM to reason in a chain of thoughts. We already did this a one-step version with the Python palindrome structured data example to successfully get optimized code, but we can do a lot more.
We’ll now introduce the Union typing operator, which specifies the list of data types that the field can be, e.g. Union[str, int] means the output can be a str or int. But if you use the Union operator on a nested class, then many more options open as the model can choose from a set of schemas!
Let’s make a few to allow ChatGPT to make and qualify thoughts before returning a final result.
from typing import Union
class Background(BaseModel):
"""A setup to the background for the user."""
background: str = fd("Background for the user's question", min_length=30)
class Thought(BaseModel):
"""A thought about the user's question."""
thought: str = fd("Text of the thought.")
helpful: bool = fd("Whether the thought is helpful to solving the user's question.")
flawed: bool = fd("Whether the thought is flawed or misleading.")
class Answer(BaseModel):
"""The answer to the user's question"""
answer: str = fd("Text of the answer.")
score: int = fd(
"Score from 1 to 10 on how correct the previous answer is",
min_value=1,
max_value=10,
)
class reason_question(BaseModel):
"""Returns a detailed reasoning to the user's question."""
reasonings: list[Union[Background, Thought, Answer]] = fd(
"Reasonings to solve the users questions.", min_length=5
)
Therefore, for each reasoning, the model can pick one of the 3 schemas, although it will require a robust system prompt for it to behave in the order we want.
system_prompt = """
You are the most intelligent person in the world.
You will receive a $500 tip if you follow ALL these rules:
- First, establish a detailed Background for the user's question.
- Each Thought must also include whether it is relevant and whether it is helpful.
- Answers must be scored accurately and honestly.
- Continue having Thoughts and Answers until you have an answer with a score of atleast 8, then immediately respond with a FinalAnswer in the style of an academic professor.
"""
Lastly, we need a good question to stump the AI. A popular Tweet from this week pointed out that even GPT-4 can comically fail if you ask it a brainteaser that it cannot have memorized, such as 23 shirts take 1 hour to dry outside, how long do 44 shirts take?.
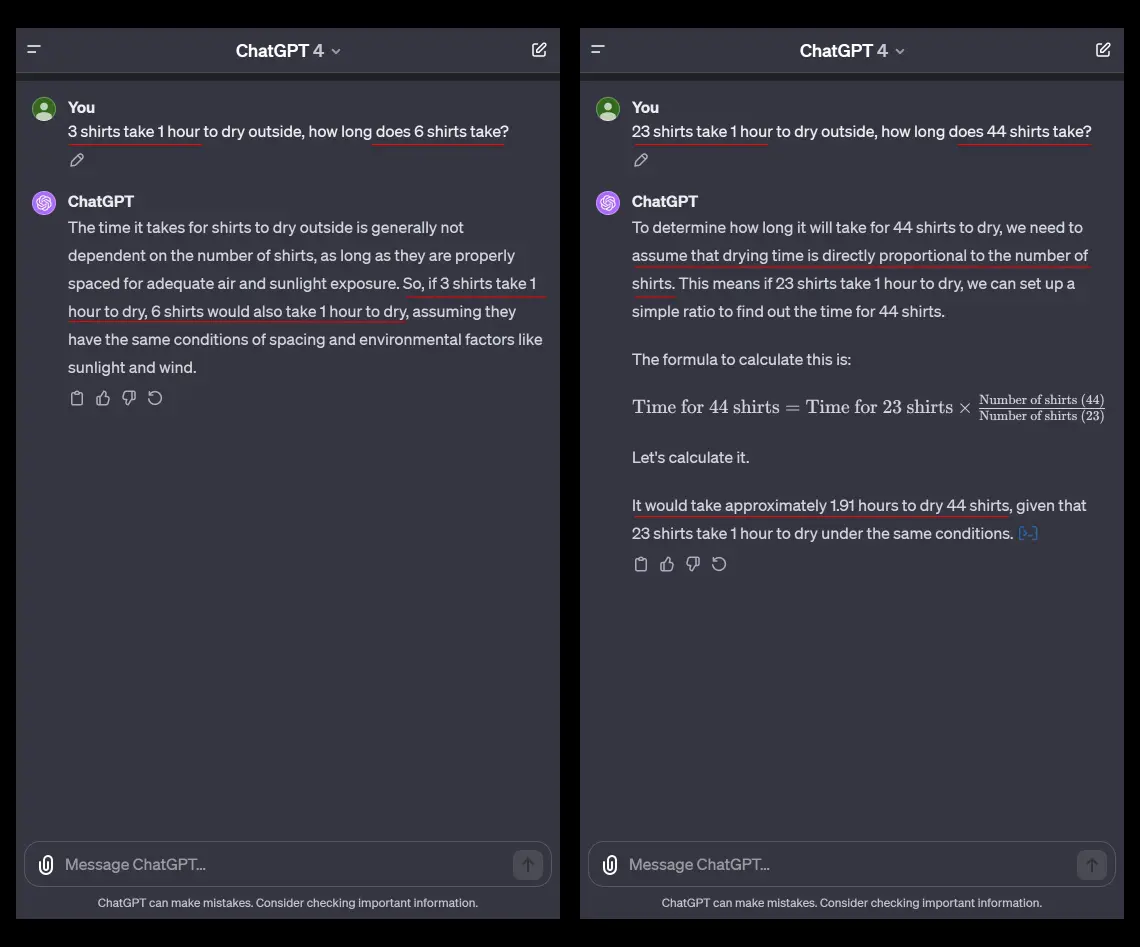
Wow! GPT-4 is superfast at being wrong. via @abacaj
Only one way to find out! Unfortunately, all of this complexity makes the results unstable with gpt-3.5-turbo so instead I use GPT-4 Turbo / gpt-4-1106-preview.
response_structured = ai(
"23 shirts take 1 hour to dry outside, how long do 44 shirts take?",
output_schema=reason_question,
system=system_prompt.strip(),
)
{
"reasonings": [
{
"background": "The user is asking about the drying time for shirts when hung outside. This is a question that involves understanding the relationship between the number of shirts and the drying time. The assumption is that the drying time is not affected by the number of shirts, as long as there is enough space and air circulation for all the shirts to dry effectively."
},
{
"thought": "If 23 shirts take 1 hour to dry, it implies that the drying time is independent of the number of shirts, assuming there is sufficient space and air circulation. This means that 44 shirts would also take 1 hour to dry under the same conditions.",
"helpful": true,
"flawed": false
},
{
"thought": "If the drying rack or space available for drying the shirts is limited, then drying 44 shirts might take longer because they would have to be dried in batches.",
"helpful": true,
"flawed": false
},
{
"thought": "The question does not specify the conditions under which the shirts are drying. Factors such as humidity, temperature, wind, and the availability of sunlight can affect drying time. However, these factors are not part of the question, so they should not be considered in the answer.",
"helpful": true,
"flawed": false
},
{
"thought": "The question might be interpreted as a direct proportionality problem, where twice the number of shirts would take twice as long to dry. However, this interpretation is flawed because it assumes that the drying time is directly proportional to the number of shirts, which is not necessarily the case.",
"helpful": true,
"flawed": true
},
{
"answer": "44 shirts would take the same amount of time to dry as 23 shirts, which is 1 hour, assuming that all shirts have enough space and air circulation to dry effectively.",
"score": 9
}
]
}
Not bad! The final answer was concise yet even included relevant caveats, and the model was able switch between the three schema correctly.
How about another brainteaser? There is an infamous “sister logic puzzle” used to test out up-and-coming open-source large language models:
response_structured = ai(
"Kayley has three brothers. Each of her brothers has two sisters. How many sisters does Kayley have?",
output_schema=reason_question,
system=system_prompt.strip(),
)
{
"reasonings": [
{
"background": "This is a classic example of a logic puzzle that is often used to test one's ability to process information and avoid being misled by assumptions. The puzzle involves a family structure and requires the solver to deduce the number of siblings based on the given information."
},
{
"thought": "The question might be trying to trick the reader into thinking that each brother has different sisters.",
"helpful": true,
"flawed": false
},
{
"thought": "If Kayley has three brothers and each brother has two sisters, it might seem like there are six sisters in total.",
"helpful": false,
"flawed": true
},
{
"thought": "Since the brothers are Kayley's siblings, they must share the same sisters.",
"helpful": true,
"flawed": false
},
{
"thought": "The puzzle is designed to test comprehension and logical reasoning, not mathematical computation.",
"helpful": true,
"flawed": false
},
{
"answer": "Kayley has one sister.",
"score": 10
}
]
}
In this case the AI may have gone too meta, but it still arrived at the correct answer.
That said, GPT-4 is known for handling these types of difficult abstract questions without much effort, but it’s still interesting to see how successfully it can “think.”
Structured Data With Open-Source LLMs
Speaking of open-source large language models, they have been growing in efficiency to the point that some can actually perform better than the base ChatGPT. However, very few open-source LLMs explicitly claim they intentionally support structured data, but they’re smart enough and they have logically seen enough examples of JSON Schema that with enough system prompt tweaking they should behave. It’s worth looking just in case OpenAI has another existential crisis or if the quality of ChatGPT degrades.
Mistral 7B, the new darling of open-source LLMs, apparently has structured data support on par with ChatGPT itself. Therefore, I tried the latest Mistral 7B official Instruct model with a quantized variant via LM Studio (mistral-7b-instruct-v0.2.Q6_K.gguf), to see if it can handle my answer_question function that ChatGPT nailed. The system prompt:
Your response must follow this JSON Schema:
{
"description": "Returns an answer to a question the user asked.",
"properties": {
"answer": {
"description": "Answer to the user's question.",
"type": "integer"
},
"ones_name": {
"description": "Name of the ones digit of the answer.",
"type": "string"
}
},
"required": ["answer", "ones_name"],
"type": "object"
}
And then asking How many miles is it from San Francisco to Los Angeles? while seting temperature to 0.0:
{
"answer": 383,
"ones_name": "three"
}
Close enough! Unfortunately after testing the optimized Python palindrome schema, it ignored the schema completely, so this approach may only work for simple schema if the model isn’t explicitly finetuned for it.
What’s Next For Structured Data in AI?
Most of these well-performing examples were done with the “weak” GPT-3.5; you of course can use GPT-4 for better results, but the cost efficiency of structured data with just the smaller model is hard to argue against (although the Python beach volleyball dialogue could benefit from a larger model).
Structured data and system prompt engineering saves a lot and time and frustration for working with the generated text as you can gain much more determinism in the output. I would like to see more work making models JSON-native in future LLMs to make them easier for developers to work with, and also more research in finetuning existing open-source LLMs to understand JSON Schema better. There may also be an opportunity to build LLMs using other more-efficient serialization formats such as MessagePack.
At OpenAI’s November DevDay, they also introduced JSON Mode, which will force a normal ChatGPT API output to be in a JSON format without needing to provide a schema. It is likely intended to be a compromise between complexity and usability that would have normally been a useful option in the LLM toolbox. Except that in order to use it, you are required to use prompt engineering by including “JSON” in the system prompt, and if you don’t also specify a field key in the system prompt (the case in the documentation example), the JSON will contain a random key. Which, at that point, you’re just implementing a less-effective structured data schema, so why bother?
There is promise in constraining output to be valid JSON. One new trick that the open-source llama.cpp project has popularized is generative grammars, which constrain the LLM generation ability to only output according to specified rules. There’s latency overhead with that technique especially if the model is hosted on a discrete GPU, so it will be interesting to watch how that space develops.
Despite the length of this blog post, there’s still so much more than can be done with schemas: pydantic’s documentation is very extensive! I’ve been working with structured data for LLMs ever since GPT-2 with mixed success since the base models weren’t good enough, but with LLMs now being good enough to maintain a JSON schema extremely well, I think AI text generation techniques will shift, and I’ll keep simpleaichat up-to-date for it.
You can view the Jupyter Notebooks used to generate all the structured data outputs in this GitHub Repository.
Thanks to Simon Willison for reading and giving feedback on a draft of this post!
Assuming you’re not picky about the “no non-alphanumeric” implied constraint of testing for a palindrome. ↩︎
Prompt engineering is as much engineering as social engineering. ↩︎
I’m also not a fan of ChatGPT function calling as-intended-to-be-used since at best, it saves you the API call needed to select a tool in exchange for having to trust OpenAI’s black box to select the correct tool without being able to debug, and furthering API lock-in for your app. It’s a bad tradeoff. ↩︎
No, this blog post isn’t a ploy just to covertly promote my own Python library: it does genuinely save a lot of boilerplate code over the Python ChatGPT library and this post is long enough as-is. ↩︎
If you swapped the order of the
answerand theone_digitsfields in the schema, then the model returns{"ones_name": "miles", "answer": 382}because it didn’t get the hint from the answer! ↩︎
